Creating repositories that use the Java Persistence API is a cumbersome process that takes a lot of time and requires a lot of boilerplate code. We can eliminate some boilerplate code by following these steps:
- Create an abstract base repository class that provides CRUD operations for entities.
- Create the concrete repository class that extends the abstract base repository class.
The problem of this approach is that we still have to write the code that creates our database queries and invokes them. To make matters worse, we have to do this every time when we want to create a new database query. This is a waste of time.
What would you say if I would tell you that we can create JPA repositories without writing any boilerplate code?
The odds are that you might not believe me, but Spring Data JPA helps us to do just that. The website of the Spring Data JPA project states that:
Implementing a data access layer of an application has been cumbersome for quite a while. Too much boilerplate code has to be written to execute simple queries as well as perform pagination, and auditing. Spring Data JPA aims to significantly improve the implementation of data access layers by reducing the effort to the amount that's actually needed. As a developer you write your repository interfaces, including custom finder methods, and Spring will provide the implementation automatically
This blog post provides an introduction to Spring Data JPA. We will learn what Spring Data JPA really is and take a quick look at the Spring Data repository interfaces.
Let's get started.
What Spring Data JPA Is?
Spring Data JPA is not a JPA provider. It is a library / framework that adds an extra layer of abstraction on the top of our JPA provider. If we decide to use Spring Data JPA, the repository layer of our application contains three layers that are described in the following:
- Spring Data JPA provides support for creating JPA repositories by extending the Spring Data repository interfaces.
- Spring Data Commons provides the infrastructure that is shared by the datastore specific Spring Data projects.
- The JPA Provider implements the Java Persistence API.
The following figure illustrates the structure of our repository layer:

At first it seems that Spring Data JPA makes our application more complicated, and in a way that is true. It does add an additional layer to our repository layer, but at the same time it frees us from writing any boilerplate code.
That sounds like a good tradeoff. Right?
Introduction to Spring Data Repositories
The power of Spring Data JPA lies in the repository abstraction that is provided by the Spring Data Commons project and extended by the datastore specific sub projects.
We can use Spring Data JPA without paying any attention to the actual implementation of the repository abstraction, but we have to be familiar with the Spring Data repository interfaces. These interfaces are described in the following:
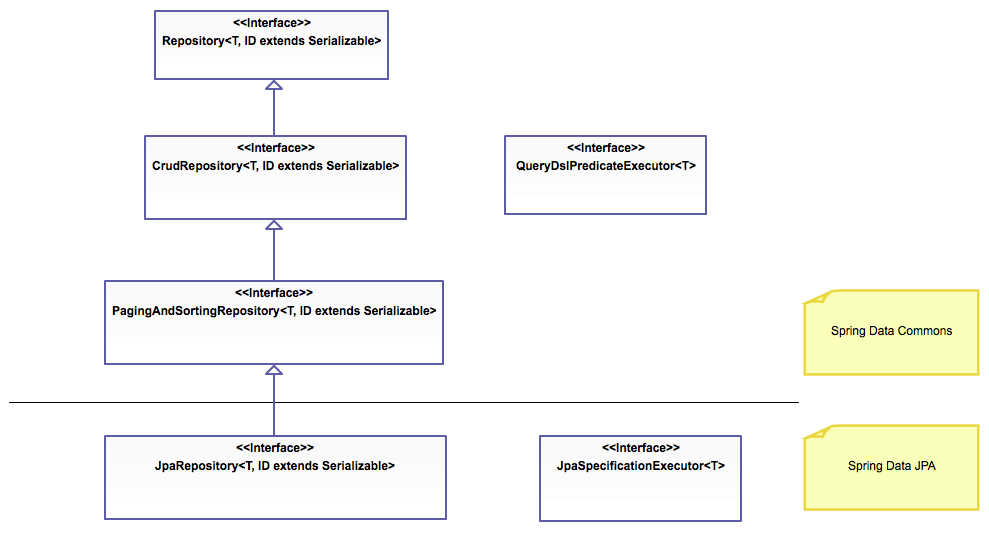
First, the Spring Data Commons project provides the following interfaces:
- The Repository<T, ID extends Serializable> interface is a marker interface that has two purposes:
- It captures the type of the managed entity and the type of the entity’s id.
- It helps the Spring container to discover the "concrete" repository interfaces during classpath scanning.
- The CrudRepository<T, ID extends Serializable> interface provides CRUD operations for the managed entity.
- The PagingAndSortingRepository<T, ID extends Serializable> interface declares the methods that are used to sort and paginate entities that are retrieved from the database.
- The QueryDslPredicateExecutor<T> interface is not a "repository interface". It declares the methods that are used to retrieve entities from the database by using QueryDsl Predicate objects.
Second, the Spring Data JPA project provides the following interfaces:
- The JpaRepository<T, ID extends Serializable> interface is a JPA specific repository interface that combines the methods declared by the common repository interfaces behind a single interface.
- The JpaSpecificationExecutor<T> interface is not a "repository interface". It declares the methods that are used to retrieve entities from the database by using Specification<T> objects that use the JPA criteria API.
The repository hierarchy looks as follows:
That is nice, but how can we use them?
That is a fair question. The next parts of this tutorial will answer to that question, but essentially we have to follow these steps:
- Create a repository interface and extend one of the repository interfaces provided by Spring Data.
- Add custom query methods to the created repository interface (if we need them that is).
- Inject the repository interface to another component and use the implementation that is provided automatically by Spring.
Let's move on and summarize what we learned from this blog post.
Summary
This blog post has taught us two things:
- Spring Data JPA is not a JPA provider. It simply "hides" the Java Persistence API (and the JPA provider) behind its repository abstraction.
- Spring Data provides multiple repository interfaces that are used for different purposes.
The next part of this tutorial describes how we can get the required dependencies.
Many Thanks!
You are welcome!
Nice Post.. Mr Petri
Excellent post
Thank you! I am happy to hear that you liked this blog post.
Keep all your jobs in Spring, they are very good, excellent
Thanks for all Petri.
Regards
Thank you for your kind words. I really appreciate them.
Enjoyable reading and very helpful in my understanding of data persistence and web app flow.
Thanks
Hi Michael,
you are welcome. I am happy to hear that this blog post was useful to you.
Hi Petri ,
It's very easy and nice to read,
Thanks
Vasu
Hi Vasu,
You are welcome. I am happy to hear that blog post was useful to you.
Can you elaborate n+1 select problem in jpa in detail.
Check out this blog post.
Hi Petri,
Firstly thanks for the link and the blog.
I am eager to know what is the root cause behind n+1 select problem?
Because in my application for some specific reference in an entity are getting n+1 select problem,not for all the entity.
Unfortunately it's impossible to answer to that question because I don't know the answers to the following questions:
However, the most common cause of the N+1 select problem is that you query an entity and iterate the results (a collection) in a lazy fashion.
Check out this blog post. It should help you to get more information about the typical performance problems which are caused by JPA.
Hi Petri,
It's been well over a year since you started writing these blogs? Has the Spring Data JPA APIs changed much? I asked because I'm interested in checking your tutorials out.
Thanks.
Hi Samuel,
As far as I know, there hasn't been any major changes to existing APIs. In other words, my Spring Data JPA tutorial should be up-to-date.
Precise and really helpful. Many Thanks.
You are welcome.
Excellent explanation.
Thank you for your kind words. I really appreciate them.
What a great post! Thanks for taking the time to shade some light on Spring Data JPA!
You are welcome! I am happy to hear that this post was useful to you.
Thanks Petri.
Which version of Springs?
You are welcome. I am happy to hear that this blog post was useful to you.
This tutorial uses the Spring IO Platform 1.1.2.RELEASE. This means that the examples use Spring Data JPA 1.7.2.RELEASE.
Nice post. Thanks for your sharing.
You are welcome!
Very Nice Post .i am happy to conect you
thank you
Thank you for your kind words. I really appreciate them.
Thank you very much! Finally i understood Spring
It was very nice to read and follow
Thanks! Keep it up
Thank you for your kind words. I really appreciate them.
Thanks a lot!!!
You are welcome.
Wonderful article with simple words and easy to understand the concepts. Good Job.. Love to read & learn more..
Thank you for your kind words. I really appreciate them.
Excellent explanation, simple and concise!
Thank you! I am happy to hear that you liked this blog post.
Thank you for this,It's very helpful to me!
This tutorial is really helpful for me. Thanks for your post. I really appreciate.
You are welcome.
thanks, big help
You are welcome.
Its a great easy to read n understandable blog post. And you responding to every comment is beyond practicality. Outstanding work petri! Thanks for your efforts.
Thank you for your kind words. I really appreciate them!
Thank you for Spring Data JPA series, there are many topics that aren't anywhere.
You are welcome. I am happy to hear that this series has been useful to you.