Every developer must understand two things:
- Architecture design is necessary.
- Fancy architecture diagrams don’t describe the real architecture of an application.
The real architecture is found from the code that is written by developers, and if we don’t design the architecture of our application, we will end up with an application that has more than one architecture.
Does this mean that developers should be ruled by architects?
No. Architecture design is far too important to be left to the architects, and that is why every developer, who wants to be more than just a type writer, must be good at it.
Let’s start our journey by taking a look at the two principles that will help us to design a better and a simpler architecture for our Spring powered web application.
The Two Pillars of a Good Architecture
Architecture design can feel like an overwhelming task. The reason for this is that many developers are taught to believe that architecture design must be done by people who are guardians of a mystical wisdom. These people are called software architects.
However, the task itself isn’t so complicated than it sounds:
Software architecture is the high level structure of a software system, the discipline of creating such a high level structure, and the documentation of this structure.
Although it is true that experience helps us to create better architectures, the basic tools of an architecture design are actually quite simple. All we have to do is to follow these two principles:
1. The Separation of Concerns (SoC) Principle
The Separation of Concerns (SoC) principle is specified as follows:
Separation of concerns (SoC) is a design principle for separating a computer program into distinct sections, such that each section addresses a separate concern.
This means that we should
- Identify the "concerns" that we need to take care of.
- Decide where we want to handle them.
In other words, this principle will help us the identify the required layers and the responsibilities of each layer.
2. The Keep It Simple Stupid (KISS) principle
The Keep It Simple Stupid (KISS) principle states that:
Most systems work best if they are kept simple rather than made complicated; therefore simplicity should be a key goal in design and unnecessary complexity should be avoided.
This principle is the voice of reason. It reminds us that every layer has a price, and if we create a complex architecture that has too many layers, that price will be too high.
In other words, we should not design an architecture like this:

I think that John, Judy, Marc, and David are guilty of mental masturbation. They followed the separation of concerns principle, but they forgot to minimize the complexity of their architecture. Sadly, this is a common mistake, and its price is high:
- Adding new features takes a lot longer than it should because we have to transfer information through every layer.
- Maintaining the application is pain in the ass impossible because no one really understands the architecture, and the ad-hoc decisions, that are made every, will pile up until our code base looks like a big pile of shit that has ten layers.
This raises an obvious question:
What kind of an architecture could serve us well?
Three Layers Should Be Enough for Everybody
If think about the responsibilities of a web application, we notice that a web application has the following "concerns":
- It needs to process the user's input and return the correct response back to the user.
- It needs an exception handling mechanism that provides reasonable error messages to the user.
- It needs a transaction management strategy.
- It needs to handle both authentication and authorization.
- It needs to implement the business logic of the application.
- It needs to communicate with the used data storage and other external resources.
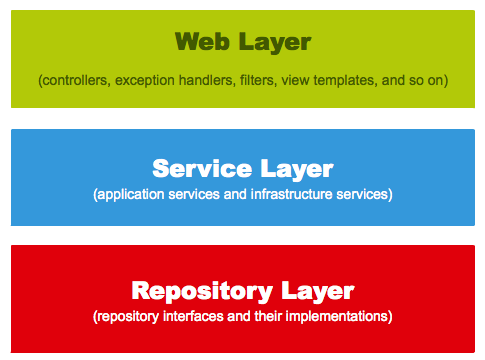
We can fulfil all these concerns by using "only" three layers. These layers are:
- The web layer is the uppermost layer of a web application. It is responsible of processing user’s input and returning the correct response back to the user. The web layer must also handle the exceptions thrown by the other layers. Because the web layer is the entry point of our application, it must take care of authentication and act as a first line of defense against unauthorized users.
- The service layer resides below the web layer. It acts as a transaction boundary and contains both application and infrastructure services. The application services provides the public API of the service layer. They also act as a transaction boundary and are responsible of authorization. The infrastructure services contain the "plumbing code" that communicates with external resources such as file systems, databases, or email servers. Often these methods are used by more than a one application service.
- The repository layer is the lowest layer of a web application. It is responsible of communicating with the used data storage.
The high level architecture of a classic Spring web application looks as follows:
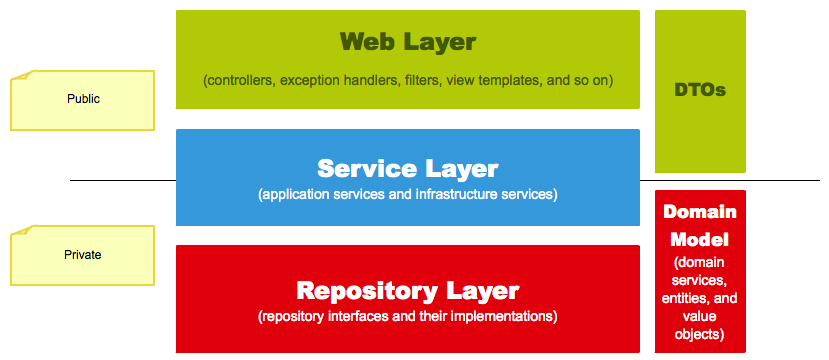
The next thing that we have to do is to design the interface of each layer, and this is the phase where we run into terms like data transfer object (DTO) and domain model. These terms are described in the following:
- A data transfer object is an object that is just a simple data container, and these objects are used to carry data between different processes and between the layers of our application.
- A domain model consists of three different objects:
- A domain service is a stateless class that provides operations which are related to a domain concept but aren’t a “natural” part of an entity or a value object.
- An entity is an object that is defined by its identity which stays unchanged through its entire lifecycle.
- A value object describes a property or a thing, and these objects don’t have their own identity or lifecycle. The lifecycle of a value object is bound to the lifecycle of an entity.
Now that we know what these terms mean, we can move on and design the interface of each layer. Let’s go through our layers one by one:
- The web layer should handle only data transfer objects.
- The service layer takes data transfer objects (and basic types) as method parameters. It can handle domain model objects but it can return only data transfer objects back to the web layer.
- The repository layer takes entities (and basic types) as method parameters and returns entities (and basic types).
This raises one very important question:
Do we really need data transfer objects? Why cannot we just return entities and value objects back to the web layer?
There are two reasons why this is a bad idea:
- The domain model specifies the internal model of our application. If we expose this model to the outside world, the clients would have to know how to use it. In other words, the clients of our application would have to take care of things that don’t belong to them. If we use DTOs, we can hide this model from the clients of our application, and provide an easier and cleaner API.
- If we expose our domain model to the outside world, we cannot change it without breaking the other stuff that depends from it. If we use DTOs, we can change our domain model as long as we don’t make any changes to the DTOs.
The "final" architecture of a classic Spring web application looks as follows:
There Are Many Unanswered Questions Left
This blog post described the classic architecture of a Spring web application, but it doesn’t provide any answers to the really interesting questions such as:
- Why the layer X is responsible of the concern Y?
- Should our application have more than three or less than three layers?
- How should we design the internal structure of each layer?
- Do we really need layers?
The reason for this is simple:
We must learn to walk before we can run.
The next blog posts of this tutorial will answer to these questions.
Why use DTOs in whole web layer? Isn't that too much work? I think it depends on the frameworks used in presentation layer and the application itself. I mostly use entities in parts of presentation layer, which are processed on the server. But if I need to send to the presentation layer something a little bit different than what's in the database, or if I send some object in form of JSON / XML to the client, I always use DTOs. That's my 2 cents.
Thank you for writing this comment. I was expecting that someone would ask this, and I was going to cover this in the next parts of this tutorial. However, since you happened to ask it here, I will provide a more practical answer.
If we think about the use cases that we have in real life applications, we can identify four common use cases:
We need to return a list. Typically list items either contain only a few fields of the entity or they contain fields from multiple entities. If I need to do something like this, I will create a repository method that returns a collection of DTOs. Typically I will use the
JdbcTemplateandBeanPropertyRowMapperclasses for this purpose.The reason why I do this is that this is the fastest way to do this. Also, since this doesn't really make things more complicated, querying DTOs makes perfect sense.
We need to show the information of an item.. This is a bit tricky use case because returning an entity makes perfect sense. If I need to show the every field of an entity, why would I create a DTO object and return it instead?
Well, like I mentioned in my blog post, the domain model objects aren't meant to be exposed outside the service layer. The practical reason for this is that I don't design my domain model objects (this includes entities) to be viewed. I design them to solve a business problem. This means that it can be a bit tricky to get the relevant information from them. This is a problem because it can make my views more complicated than they should be.
On the other hand, if I return a DTO that is tailored for that specific view, my views will be very simple. Also, since I can reuse this code in the next use case, I don't really add any unnecessary code.
We need to load the information of an item to a form. This is very similar than the previous use case, and my reasons for returning a DTO instead of an entity are the same than in the previous use case.
However, there is one more reason why I won't return entities if that object is used as a form object. Because I use either the JSR 303 or JSR 349 support of Spring Framework when I validate my form objects, I need to add the required annotations to my form object class. I don't want to add these annotations to my entities because I think that my entities shouldn't be aware of the validation rules that are used when my form objects are validated.
Also, I don't want to turn my entities into an annotation nightmare.
We need to save the information that was entered to a form. My reasons for returning DTOs are the same than in the previous use case.
That is fair opinion and I used to think that way too. The biggest reason why I changed my mind was that I started querying DTOs from the database if I am inside a read-only transaction. When I noticed that this makes my code simpler and a lot faster, I decided to hide my domain model from the web layer.
By the way, if you need to transform entities into DTOs, you could use one of the following libraries: jTransfo, Dozer, or ModelMapper.
I can see pros and cons for DTOs, and I don't think they are an always or never thing.
DTOs can add a lot of maintenance overhead, especially for simple domain objects. I'd suggest that often it's not worth it. We're not all writing huge systems, sometimes we're building fairly simple applications.
But, as a domain becomes more complex, it starts to make more sense. And, as you point out, when a client of the service layer needs a different, or restricted view of data. I find myself using a DTO to provide JSON data to an AJAX service all the time.
You are right. There are no best practices or rules that are always true. It always depends from the context.
Like you said, if you write "simple" applications, you can (and often you should) use a lighter approach. On the other hand, if you write "complex" applications that have a "complicated" domain, you have to pay more attention to these things.
I plan to write more about this in the next parts of this tutorial because this is a really important topic that is often overlooked. Actually, now I started to wonder if I gave the impression that the "classic" architecture is the best choice for every situation.
Thank you for the interesting article.
JSON is currently used in most APIs. Is there a need to use DTOs when one can conveniently use a Map? I understand DTOs may allow for behavior such as validation but if it is not needed, is using a Map advisable?
I wouldn't recommend using
Mapobjects (unless I want to return aMap) because transforming domain model objects intoMapobjects (and vice versa) makes your code unreadable and error prone.If your application is so simple that you don't need DTOs, you could use Spring Data REST.
The last few years I have more and more problems with the traditional 3 layered approach. The main problem is that those are viewed as physical layers and must be represented in the package structure of your application. This leads to a technical division of your code (i..e a UserService in the service and UserRepository in the repository package) whereas they actually should be packaged together (one of the SOLID principles that things that change together belong together). IMHO there should be a functional packaging instead. Oliver Gierke wrote a nice post about it here, also Simon Brown wrote about it here. Although the classic 3-layers might work for a very basic application in the end it will almost always lead to a big ball of mud/spaghetti code.
I do like the use of DTOs in the web layer as, again the last couple of years, I notice that there is almost always a mismatch in what you want to show and how your business logic should, ideally, be implemented. I like the approach taken in the hexagonal architecture, the core is save and everything else (web layer for instance) is an adapter that plugs into the core. I always keep in mind that 'A single model cannot be optimized for web, transactions, reporting and business logic' (freely after quote I read once in a CQRS presentation).
Regarding Mapping domain to DTO I like to use mappers, Dozer is well known but an oldie and not that fast. Lately I have been looking at MapStruct.
Hi Marten,
thank you for your comment.
I have been struggling with the same problems, and I agree with you.
One of the biggest problems of the technical package structure is that you cannot create a public interface for your modules, because the package private visibility constraint is useless if you don't use the functional package structure.
I agree. It is very hard to decouple your modules when everything must be public.
I am planning to describe this approach later in this tutorial. I just wanted to describe the traditional approach first, and then reveal its weaknesses.
By the way, thank you for telling me about MapStruct. I will take a closer look at it.
Hi Petri,
Very nice post! To extend a bit on MapStruct (I'm the original author of the project): Unlike runtime-based frameworks, the idea is to generate mapping code at compile time, resulting in fast (no reflection) and dependency-free code, plus you get instant feedback on unmappable attributes etc. right in your IDE or command line build.
I'm looking forward to any feedback you may have!
Hi Gunnar,
Thank you for your kind words! I really appreciate them.
I took a quick look at the MapStruct User Guide and it looks very promising. I will use it in my hobby project and give you some feedback about it.
... sorry to chime in here. I def see a lot of people push the idea of things that change together stay together in packaging. I am not sure though that this includes backend code with front end code. I am seeing especially with Spring's focus on Spring Boot and Microservices a movement to separating theses layers not only in packages but separate projects. A lof of Angular apps now seem to want the angular side being constructed with their set of tools...(Yeoman and such) and the back end constructed with Maven or other using spring boot to create this layer. You end up with multiple micro services that construct the project as a whole. So I am not sure how I get theses two concept/ directions to live together well.
I am not an expert of the microservices architecture, but if I would have to split a monolithic application into an application that uses the microservices architecture, I wouldn't do this by using "horizontal layering".
Instead I would use vertical slicing where each microservice implements one function (or all related functions). Also, I would probably create a few microservices that would handle cross cutting concerns such as authentication and authorization (if these are needed). This way I can deploy an individual microservice without breaking the whole application. Of course, the UI is an exception to this rule.
Here are some resources that have guided my thinking:
Also, it is good to understand that one reason why Netflix (and other cool companies) are using the microservices architecture is that they have almost unreal scalability requirements, and the microservices architecture helps them to meet these requirements. Are you sure that your application has to scale like a king? If the answer to this question is no, using the microservices architecture might not be worth it.
In regards to DTOs in the web layer, I used the Spring HATEOAS Resource approach and liked it quite a bit.
I haven't used it yet, but I would love to try it out in the future. I guess I will use it in my hobby project.
Very good post that allows this old programmer to keep learning.
Thank you! I really appreciate your kind words.
Great Post Petri...
I worked on a project earlier this year using traditional EJB where the layers were separated in dedicated ears. The public facing ear was essentially a REST entry-point for inbound communication to the app that relayed via JMS to a central ear. All the domain logic and services were in the central ear. To manage having access to common functionality a dedicated ear was included as a build dependency in Maven under the same groupId. This architecture worked pretty well but it was really hard to keep up with where things were being called from when it came to to debug... That was not so fun.
refreshing & timely approach to an timeless problem.
agreed, real architecture is baked in, "the code that is written by developers"
Thank you for your kind words. I really appreciate them.
Thanks for the informative post!
Wondering how you will implement DTOs repositories to fetch data from multiple domain entities while adhering to DDD principles.
You are welcome. It is nice to know that this blog post was useful to you.
I started to wonder if I am missing something because I don't see how querying DTOs could break the DDD principles. Could you shed some light on your question? What principles are you talking about?
No, No, what I mean is if you can provide an example about this.
Because, as I understand from DDD, repositories are belongs to the domain layer and will return only entities.
Please correct me If I'm wrong.
I agree that if we think about "pure" DDD, repositories are used to fetch entities from the data storage, and querying DTOs violates that principle.
That being said, I don't follow a principle when it doesn't make sense to do so. For example, if I can get better performance by querying DTOs and I am inside a read-only transaction, I will query DTOs (if I really need the better performance).
By the way, do you want to know how you can query DTOs with Spring, or do you just want to understand the general idea?
It's a useful blog, thanks Petri.
I would like to know how we can query DTOs with Spring? An example will be useful.
Hi,
If you are using Spring Data JPA, you can follow the advice given in this blog post (it has sample code). On the hand, if you don't want to use Spring Data JPA, you can also use
JdbcTemplate.Thanks for your post. Can you give a classic demo with the classic way ?
You are welcome.
If you want to see applications that use this approach, you can take a look at the old example applications of my Spring Data JPA tutorial.
By the way, I don't use the "classic" package structure anymore because it causes too many problems.
Thanks, very nice post!
Thank you for your kind words. I really appreciate them.
Thanks for your post Petri. I really enjoyed reading it and it is very useful. Regardless of this, do you have any sample code? Maybe using Spring MVC?
Thank you for your kind words. I really appreciate them.
Yes.
I hope that this answered to your question.
I am going to describe this transition in the next parts of this tutorial. Thank you for reminding me that I should start writing the next part of this tutorial.
Nice blog post. My colleagues and I constantly have this conversation. I agree with the layered approach and use it almost all the time.
We've use maven modules to separate our layers to ensure this consistency can not be broken.
By that, I mean the web module depends on the service module and the service module depends on the repository module and so on.
This helps us ensure that no one tries to use domains in the web layer or tries to call a dao in the web layer.
Cool!
Thanks!
Hi Petri
Nice article & Interesting debate you have started here. But I am more curcious for your second part of this blog. I can't find links for that.. can you help me here..
Hi Umesh,
I haven't written the second part of this tutorial yet. I have tried writing it a few times, but since I wasn't happy with the finished posts, I decided to not publish them. Do you have any questions that should be answered by the second part of this tutorial?
Thank you for this excellent post!
I used the same cartoon about the layer architecture to illustrate what was going on at a place I used to work.
Totally agree as well about not following principles when it doesn't make sense.
Thank you for your your kind words. It's great to hear that this blog post was useful to you!
Hi Petri,
Really nice article and I still wait for the subsequent parts. I'd like to share my thoughts as well. What to you think about introducing *Req, *Res objects that are equivalents of request and response being sent. This objects will be annotated will all validation annotations and will be used only to exchange data with the clients. Then DTO is only used to communicate among services and between services and presentation layer. Role of entities remains the same, it finishes in services layer. I know it might be an overkill - almost 3 identical structures are created. However I see projects where it would be useful and introduce some tidiness. What do you thing? What about efficient mapping?
This does sound like an overkill, but on the other hand, I don't want to judge this as a bad idea just because I don't understand it. You mentioned that you have some ideas of projects that could benefit from this. Could you share these examples here?
I would love to read more about your idea because it seems that I could learn something new.
Hi Petri,
Nice and clean post, I am definitely looking for other posts on your blog.
One question on this one. The exception handler is in the web layer, totally agree.
Where should I put my exception classes? If I put them within the domain model, the service layer and repository layer have access to it but not the web layer. If I put them into the service layer, first it doesn't seem right because they are just some entities, no business inside and more, the repository layer also needs to throw exceptions and would break the rule "The components that belong to a specific layer can use the components that belong to the same layer or to the layer below it."
Not sure if my question is clear, basically I want to know where exceptions belong in the architecture.
Thanks a lot,
Jojo
Hi Jojo,
Thank you for your kind words. I really appreciate them.
I put them to the package that contains the class which throws them. If an exception is thrown by multiple classes that aren't in the same package, I put them to the parent package of these classes or to some other package that makes sense (I know that this is a bit vague, but it really depends from the exception).
The reason why I do this is that I don't use the "traditional architecture" anymore (see Marten's comment for more details). I just wrote this blog post because you need to understand the classic architecture before you can understand why using other options is a better choice.
Hi Petri, what makes this such a good article is the way you have demystified a lot of the hysteria surrounding design/architecture. If you would be kind enough to help me understand your design better, as I am also interested in the DTO/Entity approach.
If you domain objects properties/fields are well hidden, how do you re-hydrate a rich data model from the datastore? I ask because I have thought about this in the past and the only way I could find was to add a public facing class (factory?) that lived in the same package as the domain objects and therefore had visibility to protected/package level properties and could re-build these where as other packages had no visibility.
Is this a strict or relaxed layered architecture? Are the read only transactions that return DTO's called directly from the web layer or through a service facade?
Lastly, some examples of a vertical packaging structure and deployable packages would be great for reference, I too have stuck with the traditional horizontal / layer approach seen applications end up as a big ball of mud.
Thanks.
Hi Thorbs,
I create mapper components that transform entity objects into DTO objects. Of course the problem is that this that I have to write a lot of boilerplate code. That is why I try to reduce the amount of boilerplate code by using Dozer, jTransfo, or ModelMapper.
I guess it depends from the architect. ;) Typically the "classic" architecture was very strict, but I have noticed that some people are advocating an approach where layers are added only when they make things simpler. I think it's a good idea.
However, it can be a double edged sword as well. It works very well in small projects, but when the project becomes "big enough", you have modularize it or otherwise you will end up with a big ball of mud. The thing is that people don't necessarily have time (or will) to rewrite their application when they run into these problems.
Unfortunately all of my work related projects are not public :( The example application of my Spring Data JPA tutorial uses this approach, but since it is basically just a to-do list, I am not sure if it is very useful. I will probably provide a more useful example when I write the other parts of this tutorial. If you have time, you could watch this talk: Whoops! Where did my architecture go?
Thanks Petri, I appreciate your time.
You are welcome! It is fun to answer to these questions because it helps me to clarify my own thoughts about this subject, and often I learn new things while writing my answer.
Great Article.... Neat, simple and Clear...
It would have been Excellent If you had described it side side by with an Example or atleast a Diagram.
Thank you for your kinds words. I really appreciate them.
What kind of an example or a diagram would have been useful to you?
Thank you for the great article.
You have defined a domain service as a stateless class that provides operations which are related to a domain concept but aren’t a “natural” part of an entity or a value object. Can you make it a bit clearer?
Thanks
Thank you for your kind words. I really appreciate them!
This is a very good question. I suggest that you read the answers of this StackOverflow question because the discussion is really interesting and it contains many useful examples (like the Eric Evans' cargo example).
Thank you very much for your reply and the very helpful Informations. This is exactly what I have been looking for.
You are welcome!
Hi Petri,
I was going to praise you article, but it seems it's already quite liked. :)
I would like to add two reasons to use DTOs:
1. When having Hibernate or other ORM at work between the Service and Repository layers and hibernate entities are passed directly to the client instead of DTOs. If at some later point the UI has to pull data from entity’s lazy fields there is a risk that Hibernate's session may be unavailable and you will end up with the infamous lazy initialization exception. With DTO, those needed fields could be populated at DTO construction time while the session is still open;
2. It doesn’t make much sense to pass entire domain model entity with all his dependencies to the client just to show few fields like name and address - It's a waste. DTO is a perfect solution to this problem;
DTO is good practice even for "small" projects, but it has to be incorporated at early stage to reduce maintenance cost later, when the project start to grow.
Thanks.
Hi Joro,
Thank you for your kind words I really appreciate them. Also, I totally agree with you!
Hi Petri,
Thanks for good informations about Spring, I want to know that Is there any 3 layered structure model in Spring Mvc for Html page like Apache Wicket and Angular js... For example, you can create main page and sub pages which depend to the main page in Apache Wicket and Angular js. But I couldn't find a way to build this structure in Spring Mvc... Everytime I need to create new page. But if I can extend main page, it would be great and clean code.
Hi,
Spring MVC doesn't have a page concept because it is not a component based web framework like Apache Wicket.
When you are writing "normal" web applications with Spring MVC, you have to implement view templates by using one of the supported view technologies. Some of these technologies provide a way to create reusable "snippets", but these snippets are a bit different than reusable Wicket components.
If you have any additional questions, don't hesitate to ask them.
Thank you for quick reply, I want to ask a question about it. Can I create inheritable pages using with Thymeleaf. I meantioned before, I can create main pages in Apache Wicket or Angular js and then when I want to use it for sub pages, I can extend this main pages... Actually I want to learn that can I do same thing using Thymeleaf.
Hi Hasan,
Well, you can create reusable "components" and hierarchical style layouts with Thymeleaf. Take a look at this article. It explains how you can create page layouts with Thymeleaf.
Hi Petri,
Thank you so much for your inform, I've looked at that page. According to this sentence in that page, this framework not use ajax like apache wicket.
"The main disadvantage of this solution, though, is that some code duplication is introduced so modifying the layout of a large number of views in big applications can become a bit cumbersome."
As I remember, Apache wicket and Angular js use ajax in their reusable “components” . Is there any way or example for this framework ?
Hi,
You are right. Since Thymeleaf is a template engine, the HTML markup is rendered on the server.
If you want to use ajax with Spring MVC, you have to implement a REST API with Spring MVC. Also, you need to either enhance your "regular" HTML views with jQuery (or vanilla Javascript) or implement a single page application by using frameworks like AngularJS, Backbone.js, and Ember.js.
Hi Petri,
Thanks for this nice article, your blog helps me thinking about software development and architecture a lot.
In your post you mention the next part of the tutorial a few times, but I'm unable to find it. I am really looking forward to read your answer to the questions you ask at the end of this post, especially this one:
"Do we really need layers?"
Lately, I'm having more and more issues with the layered architecture (especially the data access layer / service layer), and I'm trying out the "Clean Architecture" (see e.g. https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html).
I was wondering if you have any experience with this kind of architecture, and what are your thoughts on it?
Hi Maarten,
You are welcome. I am happy to hear that this blog post was useful to you.
The reason for this is that I haven't written it yet. I wrote a few drafts but I wasn't happy with the outcome => I gave up. Maybe I should try to write it once again. Anyway, if you want to get some answers to your questions, you should read this blog post: Whoops! Where did my architecture go.
I have been experimenting with hexagonal architecture and it does look quite promising. However, since I haven't been working on a greenfield project for a while, I haven't been able to use it at work. That is why I have no first hand experience from it, but I will try to get it as soon as possible. I think that you can give it a shot and see how it goes.
If you have any additional questions, don't hesitate to ask them.
Hi! thanks! I was wondering to my self about a good architecture for a Spring MVC project. I think that I'm going in the right way after read your blog.
I do prefer to separate the three basic layers into three differents projects. Like modules with Maven. What do you think about this approach?
NOTE: Do you have some example of this architecture?
And if you need to expose some jason API but maintain the architecture where you put a API?
Hi,
I have seen that people use this approach, but I have never used it myself. To be honest, nowadays I like to split the application into "function modules". I like the approach that is described in a blog post titled: Whoops! Where did my architecture go.
Unfortunately no. If I remember correctly, all of my example applications use an adapted version of the architecture that was described on Oliver Gierke's blog post (see the link).
I put it into a separate module. The API is basically just another way to access the service layer (take a look at Ports-And-Adapters / Hexagonal Architecture). However, this doesn't mean that it is in different war file (it might be but it depends from the situation).
If you have any additional questions, don't hesitate to ask them.
You keep telling on above posts that you are going to write many things in next post like weakness of 3-tier architecture and answers of unanswered questions so can you provide link of that articles so I can go through and read?
Thanks
Hi,
unfortunately I never wrote those blog posts. I might write them in the future, but right now I simply don't have time to write blog posts (my weekly testing newsletter is the only exception). However, I recommend that you read this blog post: Whoops! Where did my architecture go. It pretty much summarizes my thoughts about this matter.
Thanks.. I will refer provided blog post.
So nice of you that you give reply of each and every questions asked to you.
Keep posting good blogs.
You are welcome! And I will.
Great post .
Use Hibernate for persistence layer , What about the DAO return DTOs ? Hibernate has a ResultTransformer that associates the fields of HQL query ( with many joins ) a DTO class. In that case should have a DTO for each query Is that right ?
I used the generic hierarchy proposed in this paper ( http://www.codesenior.com/en/tutorial/Spring-Generic-DAO-and-Generic-Service-Implementation ) but as I see believe that exposes entities in services . Have any suggestions to improve this?
For relatively small applications , the proposed architecture in his article would be appropriate?
Thanks in advance.
Hi,
I use this approach now if the queried information is not updated. In other words, if your code is executed inside a read-only transaction or your need only a few fields from another table, it's a good idea to query DTOs. And yes, you probably want to create one DTO per query.
I don't expose entities to the "outside" world (my services return DTOs) mainly because I want isolate the private data model of the application from the public data model. However, it should be fairly easy to write a generic service method that fulfill this requirement. There really is no right or wrong way to do this because the "correct" choice depends from the application. For example, if your application is "just" a CRUD application, it has totally different requirements than an application that has complex business rules.
Yes. Although I would probably take a look a look at Spring Data REST. Of course this is a good idea only if your application has a REST API.
Thanks for the reply. It has been very useful.
You are welcome.
I think that the most important thing is that if your application is small enough, it is really really hard to "ruin it". However, if your application grows over time, you need to be "tough enough" to say that the architecture of the application was not designed for a large application and you need to rethink it (if you think that the architecture is not suitable for large apps).
The problem is that it can be really hard to convince the people with power to accept this because they typically think that the original work was "wasted" if the application is redesigned. If these people don't allow you to rethink the architecture, you might want to start refactoring your CV because the project will be extra painful. To make matters worse, if the project fails, you might be blamed for it.
Hello, I want to thank you as I found this post extremely helpful. Could you(or someone else) direct me to the further posts of this tutorial? I am particularly interested in the design/structure of the service layer, though I have no doubt that the rest of the tutorial would be valuable as well. Thank you in advance!
Hi Andrew,
Unfortunately I never wrote the next part of this tutorial. Unfortunately, I am currently very busy because I am creating my testing course, but I will start writing blog posts after I have finished it . I promise that I will write the remaining parts of this tutorial after my course is finished.
However, I realize that this won't help you to find answers to your questions (at least not right now). Do have any specific questions in mind? I can either answer to your questions here or share links to other great blog posts that shed more light to this topic.
its Nice Article 5/5
Thank you for your kind words. I really appreciate them.
Hello Petri,
Thank you for this blog post !
It's very helpful, and the comments are also very cool to read.
In fact, all the comments make me think that although there are conventional architectures, the main thing is to always keep in mind that the most important thing to do is to try to choose the best solution for the current project.
Trying to do things exactly as they are described in the books maybe counterproductive for lots of projects.
On most of my web projects (spring mvc + jpa) in only use DTOs for REST api, when I have to receive or send objects.
In the classical usage of my view layer, i directly use the entities because 99% of times we only use the properties of these entities and adding DTO will cost for nothing :
- If something changes in my entity that is not used in my view layer, so it won't affect it
- if something changes in my entity that is used in my view layer, I have to modify the code where needed in the view layer.... With DTO I would have to modify the DTO(s) and also modify the view layer
I know it's not a good practice, but in projects that often change it saves lots of time not to have to replicate entity changes into DTO classes.
Regards
Hi,
Nowadays I try to avoid calling something a bad practice because it is entirely possible that X is a bad practice only when conditions Y is true and a good practice when Z is true. Most of the time we just have to make an educated decisions and follow the approach that is most suitable for us.
For example, passing entities to view layer might make sense in your situations and that is fine. You seem to be aware of the pros and cons of both options, and you made an educated decision to use entities in your view layer. I wouldn't call that a bad practice (even though I know that it is not as common as using DTOs).
> The service layer takes data transfer objects (and basic types) as method parameters. It can handle domain model objects but it can return only data transfer objects back to the web layer.
I strongly disagree with this. I would argue that the service layer -in which the business code would reside in this particular architectural setup- should not know about *any* DTO type. DTO's typically tailor to the needs of external systems such as web service consumers and database repositories.
This way the service layer is not burdened with transformational logic between the domain model and the DTO model. A Spring endpoint controller knows what is coming in and defines the contract of what should go out. Why bother the business logic with the needs every external system?
In a way this approach is like a marriage between what you call the classic Spring web application and the hexagonal architecture mentioned in this comment thread somewhere: the functional domain model is private and exclusive to the service layer (perhaps to the repository layer as well). But every external consumer with its own DTO model can 'plug' into this.
That is why our applications all have a rich Client layer (expanding your Web layer in your setup, which is rather limiting) and an Integration layer in addition to the Repository Layer. The DTO's reside in either of these two layers, keep the Service layer relatively clean (although DDD is still a viable solution to the complex-services-problem).
This is a good point. If you are writing an application that need to support multiple external consumers, you probably need an architecture that supports it.
That being said, all applications don't have this requirement, and in fact, I think that there are situations when it's perfectly fine to return entities to the client (or to the view layer).
In any case, it seems that I should write additional blog posts that describe these architectural styles. It seems that people seem to assume that I recommend using the architecture described in this post, but the truth is that this blog post was supposed to be an introduction that only describes the architecture style which used to be the "best" option for implementing Spring web applications.
Well done, good article. But in many parts the explanations are not clear enough and you didn't write any examples so its difficult to understand
Hi Erez,
Can you identify the explanations which are not clear enough or are hard to understand because there is no example code? The reason why I ask this is that I want to write better posts and this kind of feedback will help me improve my blog posts.
"If we expose our domain model to the outside world, we cannot change it without breaking the other stuff that depends from it. If we use DTOs, we can change our domain model as long as we don’t make any changes to the DTOs."
It seems to me that changes to the domain model invariably require changes to the DTOs.
Do you agree?
Do you have practical examples where this is not the case?
Hi,
It is indeed possible that you have to change both the DTO and the entity. However, there are situations when this is not the case. For example, let's assume that you are writing a to-do list application and you want to show a list that displays all open to-do entries. Also, a user can open the view to-do entry page by clicking the title of the to-do entry shown on the list page.
If you follow my advice, you have also created two DTOs:
TodoListDTOandTodoDTO. Now, if you want to add new information to your entity or rename old fields, you can decide whether or not you want to make the same changes to your DTO.For example, if you add new information to your entity, it's likely that you don't need that information on the list page. If this is the case, you can add the new information only to the
TodoDTOclass. On the other hand, if you rename the field of your entity, you can decide to not change the name of the fields found from your DTOs (this is a viable option if you are writing a public REST API).If you expose your entity to the outer world, you don't have this option. All changes are published immediately and this might break all existing clients. This is obviously a bad thing (especially if you are writing a public API).
I think I provided one in my previous answer, but I wanted to also mention that is principle is important for three different reasons:
SELECT *instead of selecting only the required information.P.S. If you are writing prototypes or internal APIs, you can pretty much ignore this advice and do the simplest thing that can possibly work.
This article is great! Wheres the next blog post on this topic?
Hi,
Thank you for your kind words. I really appreciate them. Unfortunately I haven't written the next part of this tutorial. I will continue this tutorial after I have finished my testing course.
+1
Nice blog post. My colleagues and I constantly have this conversation. We’ve use maven modules to separate our layers to ensure this consistency can not be broken.By that, I mean the web module depends on the service module and the service module depends on the repository module and so on.
Thanks a lot for this great article on spring web application framework.
Thank you for your kind words. I really appreciate them!
Great start! Nice explanation about DTO and the justification why Entities should be used in the Web Layer/UI layer.
Hoping to read the next chapters soon. Please keep writing at your convenience
Thank you for kind words. I really appreciate them.
Hello Petri, many thanks to your article and answers to all comments. It helped me to understand principles of designing a better and a simpler architecture for web application. Really hope for your next post on this topic.
Thank you for your kind words. I really appreciate them.
This post has been 4 years since it's written, but it's so helpful and it's something that everyone who uses Spring should know!! Great explanation.
Do you mind if i translate it into Korean and post it in my personal blog with the original link?
Hi,
I don't mind at all. Feel free to translate this post as long as you include a link to the original version.
Thanks :)
dto to bean and bean to dto should be in the controller?
if yes that mean if we have a complex object, we will need to do many call to service or directly repository layer to be able to find object...
Like
Car
id
contains brand
CarDto
id
brandId
In the controller
if (carDto.getId()!=null){
Car car= carRepository.findById(id);
if(car.getBrand().getId()!= brandId){
Brand brand = brandRepository.findById(brandId);
car.setBrand(brand);
}
..
}
Hi,
As I mentioned in this article, I would put this mapping code to the service layer:
This approach has two advantages:
If you have any additional questions, feel free to ask them.
I've been waiting for your next part of this tutorial for two years :)
Hyvaa article!
Hi Petri, Thanks for this nice post. I would like to ask you a question. It possible that you have services that have to call other services, and in this case making the service layer transactional doesn't seem to me a good idea. What if one service goes good, and the subsequent not? So, how would you handle the transactionality in this case, considering that making the controller transactional is not a good design.
Regards,
Valentino
Have you had a chance to write about:
Why the layer X is responsible of the concern Y?
How should we design the internal structure of each layer?
Thanks,
What is the name of this Architecture???
I am not sure if this has an official name, but I would call it a layered architecture. The most important characteristic of this architecture style is that the application is divided into layers by using technical responsibilities as selection criteria.
well explained
Well explained zaparato